Screaming Frog Log File Analyser 4.2 绿色免费版日志分析工具

Screaming Frog Log File Analyser 4.2 绿色免费版日志分析工具
宝哥软件园为您提供Screaming Frog Log File Analyser免费下载,Screaming Frog Log File Analyser是一款专业的日志分析软件。
软件大小:155MB
软件类型:国产软件
软件语言:简体中文
软件授权:共享软件
最后更新:2021-08-31 18:47:41
推荐指数:
运行环境:WinXP,Win2003,Win7,Win8,WinALL
查看次数:
尖叫青蛙日志文件分析器是一个专业的日志分析软件。尖叫青蛙日志文件分析器,专业站长使用的日志分析工具。一个完整的搜索引擎优化工具包应该包括一个网站搜索器和一个数据分析器,这就是为什么尖叫青蛙搜索引擎优化蜘蛛开发者发布了日志文件分析器。该应用程序旨在提供更广泛的搜索引擎随时间推移的行为概述,并通过仔细分析日志文件来总结您网站的SEO状态,以识别断开的链接和孤立的页面或慢速页面,这无疑将帮助您获得最佳结果,并决定何时提高网站排名。如果你需要,请到这个网站下载!
安装方式:
1.双击安装程序,进入尖叫蛙日志文件分析器安装界面。用户可以选择默认安装或自定义安装,然后单击[安装]。
2.弹出如下安装成功提示,点击【关闭】完成。
3.运行尖叫青蛙日志文件分析器,进入如下许可协议界面,然后点击【接受】。
4.然后进入软件主界面,如下图。
5.单击菜单栏上的[许可],然后选择选项下的[输入许可]。

6.运行注册机器并输入任何用户名以生成许可证密钥。
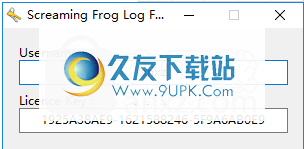
7.将注册机器上的用户名和许可证密钥复制到软件激活界面的相应列,然后单击[确定]。
8.下面弹出激活成功的提示,点击【确定】。
9.重新启动尖叫青蛙日志文件分析器程序,将其显示为活动版本。
软件特色:
关于SEO机器人行为的宝贵见解顾名思义,日志文件分析器可以分析加载的日志文件中的数据,并提供关于已爬网网址和搜索引擎机器人体验的有用信息。它会自动生成图表,并以图形方式捕捉给定时间段内事件、URL和响应代码的演变。
您可以浏览和分析统计数据,包括唯一URL的数量、事件总数、传输的平均字节数、发现的错误、重定向、客户端和服务器错误。
支持拖放操作,因此在创建新项目后可以轻松添加新文件进行分析。默认情况下,应用程序会编译和处理来自Googlebot、Bingbot、Yandex和百度的数据,但您可以轻松选择所需的bot来过滤信息。
发现不一致、错误和性能问题
日志文件分析器使所有网站所有者和搜索引擎优化专家能够访问搜索引擎抓取的网址列表,并检查访问频率。
响应代码向您显示查询引擎收到的响应,突出显示不一致和错误(如果有)。此外,通过监控下载的字节数和搜索引擎接收响应所需的时间,您可以轻松找到存在性能问题的页面。
SEO日志分析提供了一个清晰的概述
有更多关于日志文件分析器的发现。该实用程序得到了进一步的改进,并可能在搜索引擎优化专家的工具包中占有一席之地。目标是收集SEO日志文件中的数据,并以某种方式显示出来,让用户可以轻松分析大量数据,达到与SEO相关的目的。
软件功能:
通配符用户代理匹配:现在,在配置要导入到项目中的用户代理时,可以使用通配符匹配。这使得它更加灵活,尤其是当用户代理字符串定期变化时,例如新的长青Googlebot和Bingbot。
您可以从我们预定义的常见搜索引擎机器人列表中进行选择,也可以自己进行配置。
Googlebot和Bingbot之间的默认用户代理通配符匹配也进行了更新,以改进对“常青树”版本命名的跟踪。
删除参数:
在导入日志文件时,您可以提供一个参数列表,以便从URL中进行拆分和合并。
这在“新”项目配置中可用,当您知道参数或问题并需要合并数据时,这尤其有用。
新的JSON时间戳支持:
在3.0版本中,我们支持JSON格式的日志文件。没有通用的标准,所以我们使用客户提供的JSON格式,提供尽可能多的支持。
现在,这种支持已经进一步扩展,涵盖了我们的用户提供的一些不寻常的JSON时间戳示例。您所需要做的就是像往常一样拖放日志文件(或文件夹),日志文件分析器将自动检测格式并对其进行分析。
Java 11更新:
尽管这对于许多用户来说几乎没有改变,但我们已经在幕后更新到了Java 11。我们的SEO蜘蛛即将上线。
可配置的用户代理:
现在,您可以完全配置要导入到项目中的用户代理。您可以从我们常见的搜索引擎机器人用户代理的预定义列表中进行选择,或者取消选择与您无关的代理。
通过只关注目标机器人,这有助于提高性能和减少磁盘
领养。您也可以添加自己的自定义用户代理,然后保存并选择一个项目。
以前,日志文件分析器只分析谷歌、必应、Yandex和百度的僵尸工具,所以现在它允许用户监控来自其他流行搜索引擎的僵尸工具。它还允许用户分析和监控其他感兴趣的特定用户代理,如谷歌新闻或Adsbot。
包括功能:
类似于搜索引擎优化蜘蛛包含功能,您可以提供一个正则表达式列表,用于将网址导入项目。因此,如果您只想分析大型网站上的某些域或路径,如/blog/或/products/page,则可以立即这样做,以节省时间和资源,并执行更详细的分析。
新的日志文件格式支持:
日志文件分析器现在支持应用程序负载平衡日志文件格式和威瑞森边缘转换格式。
您所需要做的就是像往常一样拖放日志文件(或文件夹),日志文件分析器将自动检测其格式并开始分析。
常见问题:
为什么日志文件分析器不导入我的日志文件?最可能的原因是您要导入的文件不是日志文件,更确切地说是访问日志文件。请阅读我们的日志文件介绍指南,其中提供了支持的日志文件格式示例,以便您可以将其与自己的日志文件进行比较。
的日志文件的常见格式是:
CSV文件
JSON文件
Apache错误日志
日志文件分析器支持W3C和Apache格式的日志文件。这些日志由三个最流行的网络服务器生成:Apache、IIS和Nginx。不需要指定日志格式,当您上传日志时,日志文件分析器会自动检测格式。
如果您在导入日志时遇到任何问题,请联系我们的支持团队。
为什么不能导入CLF格式的Apache日志文件?
Apache通用日志格式(CLF)通常是为许多不同的网络服务器配置的默认格式。
不幸的是,这种格式不提供用户代理字段,这是日志文件分析器提供的分析的一部分。
您必须重新配置或要求网络服务器管理员重新配置日志格式字符串以提供用户代理字段。
这是必需的典型NCSA日志格式行:
% h % l % u % t \ " % r \ " % s % b \ " % { Referer } I \ " \ " % { User-agent } I \ " "
支持的最大日志文件大小是多少?
日志文件分析器使用数据库来存储数据。因此,可以存储的日志量将受到硬盘驱动器大小的限制。性能也受到磁盘速度的限制-固态硬盘的性能高于旋转磁盘。
网站的大小不是相关因素,而是日志文件中有多少数据。一个小而繁忙的站点可能比一个没有大量流量的大站点有更多的日志事件。
我们通常会毫无问题地导入几千兆字节的未压缩日志文件。请求数据的时间越长,必须考虑的事件越多,响应速度越慢。
为什么我的结果中缺少一些字段?
日志文件分析器可以导入信息很少的日志:时间戳、URL、响应代码和用户代理。所有其他数据都是可选的。如果您看到平均响应时间为0,这是因为导入的日志文件不包含此信息。要验证这一点,您可以查看导入的日志文件以查看其中包含的内容。如果您不熟悉,请查看我们的SEO发布日志文件指南。
要将丢失的数据添加到日志文件中,您必须更新日志配置设置,并且网络服务器管理员将熟悉这些配置设置。《搜索引擎优化日志文件指南》中链接的每个特定日志文件格式都详细描述了日志文件分析器支持的日志格式。
为什么我看到URL的响应代码不一致?
尖叫青蛙日志文件分析器显然可以直接从服务器日志中分析一段时间的数据。因此,该网址可能在历史中被破坏,然后被修复,这也解释了为什么它有不同或“不一致”的响应。
另外需要记住的一点是,如果上传一个带有相对URL的日志文件,并且在导入时必须提供站点URL,那就不是www了。还有www。网址的版本将被总结。因此,如果这是导入时提供的地址,https://screamingfrog.co.uk和https://www.screamingfrog.co.uk的事件将被汇总到https://www . screamingfrog . co . uk。不是www。该版本可以设置为301,以重定向到www。版本,因此一半的响应被重定向,另一半提供200个响应。这就是为什么我们通常建议为日志配置绝对URL。
但是,您可能还会发现服务器在负载下传递的响应不一致。
软件特色:
确定用于爬网的网址查看并分析Googlebot和其他搜索机器人可以抓取的URL、时间和频率。
查找搜索频率
了解更多关于哪些搜索机器人爬行最多,每天爬行多少个网址,以及机器人事件的总数。
查找断开的链接和错误
查找搜索引擎机器人在抓取你的网站时遇到的所有响应代码、断开的链接和错误。
审核重定向
查找搜索机器人遇到的临时和永久重定向,这可能不同于浏览器或模拟爬行网络中的重定向。
提高搜索预算
分析你网站上最常抓取的网址和目录,找出浪费,提高抓取效率。
识别大页面和慢页面
查看下载的平均字节数以及识别大页面或性能问题所需的时间。
查找未被爬网和孤立的页面
导入网址列表,并将其与日志文件数据进行匹配,以识别孤立或未知的网页或Googlebot尚未爬网的网址。
合并和比较任何数据
使用URL列导入任何数据并将其与日志文件数据进行匹配。因此,请导入爬网、指令或外部链接数据进行高级分析。
使用说明:
导入网址数据使用导入的网址数据选项卡,您可以导入CSV或Excel文件以及与网址相关的任何数据。例如,您可以从站点地图或网址导入爬网数据,或者从马奇或OSE导出主页。日志文件分析器扫描前20行中包含有效URL的列。网址必须包含协议前缀(http/https)。
可以导入多个文件,数据会根据URL自动匹配,类似VLOOKUP。目前还不能直接从站点地图导入,但是可以将站点地图网址上传到CSV/Excel和导入网址数据选项卡。
将爬网数据与日志文件事件相结合显然可以进行更强大的分析,因为它使您能够找到在web中爬网但不在日志文件中或由搜索自动化程序爬网但在以下位置找不到的URL:孤立页:爬网。
导入捕获数据
可以导出尖叫蛙SEO蜘蛛抓取的内部标签,然后直接将文件拖放到导入的URL数据标签窗口中。或者,您可以使用顶部菜单中的“导入网址数据”按钮或“项目导入网址数据”选项。这将快速将数据导入到数据库的日志文件分析器和导入的网址数据选项卡中。
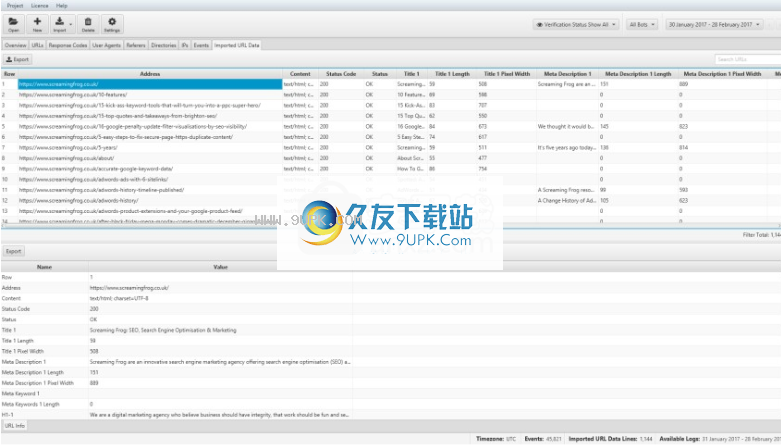
“导入的捕获数据”选项卡仅显示导入的数据,不显示任何其他内容。但是,您现在可以使用“网址”和“响应代码”选项卡中的“查看”过滤器来查看爬网数据和日志文件数据。
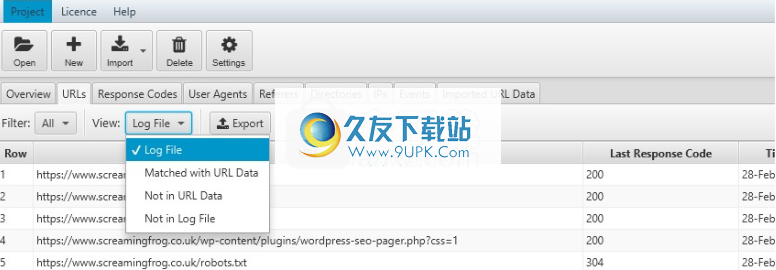
日志文件分析器默认为“日志文件”,但如果视图更改为“匹配网址数据”,它将显示爬网数据和日志文件数据(向右滚动)。
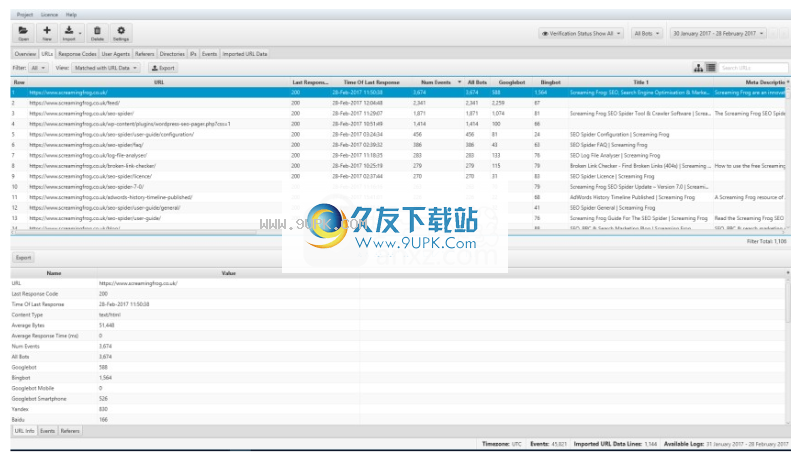
“不在网址数据中”将显示在日志中找到的网址,但不显示在导入的爬网数据中找到的网址。例如,这些可能是孤立的网址,现在已经被重定向的旧网址,或者来自外部网站的错误链接。
“不在日志文件中”将显示在爬网中找到的网址,但不在日志文件中。这些可能是搜索机器人尚未搜索到的网址,或者它们可能是例如新发布的网址。
删除导入的网址数据
您可以通过单击顶部菜单选项中的“项目清除网址数据”来快速从项目中删除“导入的网址数据”。
请注意,一旦数据被删除,除非再次导入数据,否则无法恢复。
将数据迁移到新计算机
日志文件分析器没有导出/导入项目的正式方法。当移动到新计算机时,最简单的操作是只创建一个新项目并重新导入日志文件。如果要复制现有项目,必须将其复制到项目文件夹中。您可以通过转到配置-工作区找到该文件的位置。
工作空间
您可以在此处设置另一个位置来存储项目数据。
默认情况下,日志文件分析器将项目存储在以下位置:
windows:{主驱动器号}:\用户\ {用户名\ } .来自全局文件分析器\项目的尖叫
MacO:/Users/{username}/。来自全局文件分析器/项目的尖叫
Ubuntu:/home/{username} /.来自全局文件分析器/项目的尖叫
选择替代位置时,您需要同时考虑性能和尺寸。驱动器速度越快,日志文件分析器的性能就越好。在这里选择网络驱动器是确保性能的可靠方法!日志文件分析器至少需要与导入的日志大小相同的空间。
美国联合航空公司(United Airlines)
创建新项目时,您可以配置要导入到项目中的用户代理。您可以从预定义的常见搜索引擎机器人用户代理列表中进行选择,或者取消选择与您无关的代理。通过只关注目标机器人,这有助于提高性能和减少磁盘使用。
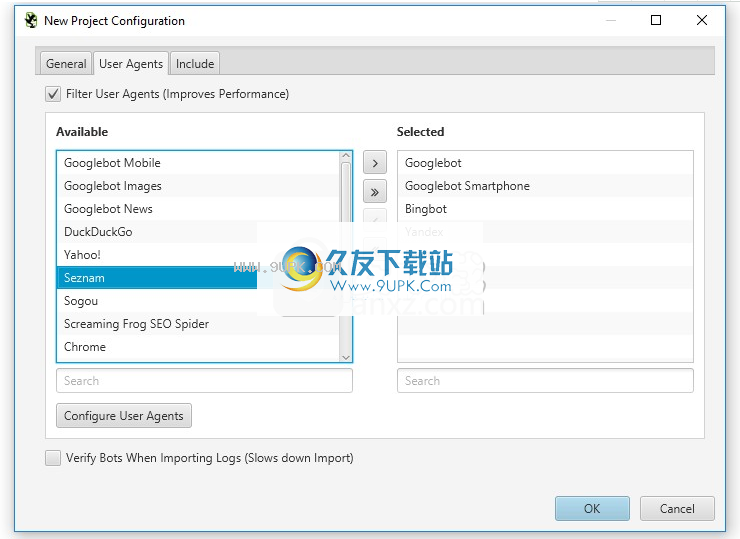
您还可以添加自己的自定义用户代理,然后保存它们并选择它们用于项目。
验证机器人
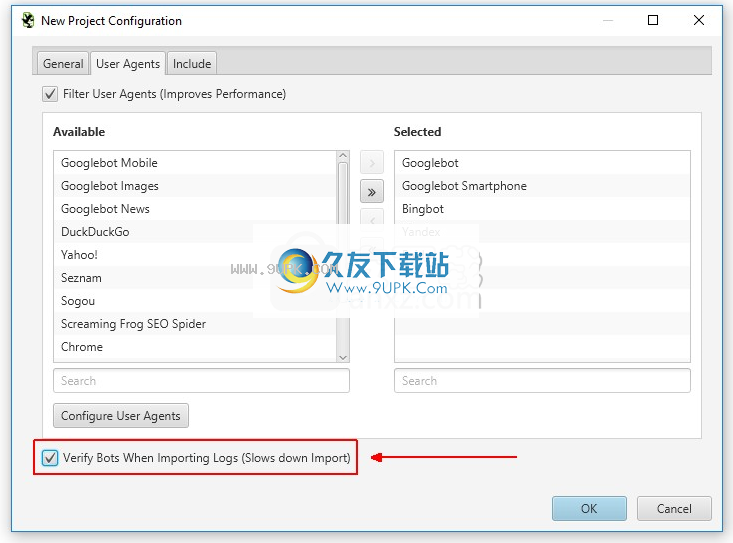
现在,您可以在上传日志文件时或在将日志文件上传到项目后查看日志引擎,以自动验证搜索引擎机器人。
上传日志时,您将有机会检查用户代理选项卡下的身份验证机器人选项。
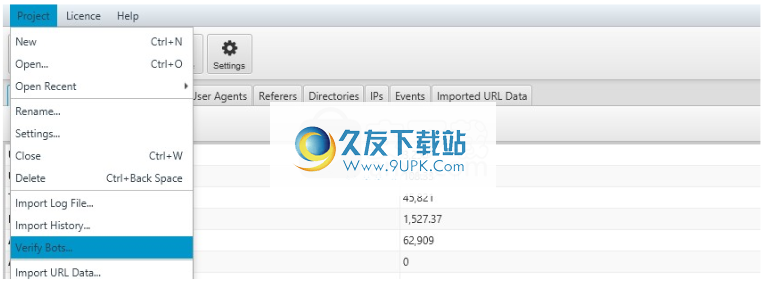
如果您已经导入了日志文件或想要追溯
验证搜索引擎机器人,可以在“项目验证机器人”菜单下完成。
搜索引擎机器人在模仿特定搜索引擎用户代理的请求时,通常会被其他机器人或爬行动物(包括我们自己的SEO Spider软件)欺骗。因此,在分析日志时,了解哪些事件是真实的,哪些事件可以打折是很重要的。
日志文件分析器将根据自己的标准验证所有主要的搜索引擎机器人。例如,对于Googlebot身份验证,日志文件分析器将执行反向DNS查找以验证匹配的域名,然后使用host命令运行正向DNS以验证其与原始请求IP相同。
要验证它,您可以使用“验证状态”过滤器来查看验证、欺骗或验证中是否有任何错误的日志事件。

Screaming Frog Log File Analyser 4.2 绿色免费版日志分析工具下载地址
- Screaming Frog Log File Analyser 4.2 绿色免费版日志分析工具:
- 暂不提供下载