详细解释JavaScript调用栈、尾部递归和手动优化
调用栈(调用栈)
调用栈是一个基本的计算机概念,这里介绍一个叫做栈框架的概念。
堆栈帧是指为函数调用单独分配的那部分堆栈空间。
当正在运行的程序从当前函数调用另一个函数时,它将为下一个函数创建一个新的堆栈框架,并进入这个堆栈框架,称为当前框架。原始函数也有一个对应的堆栈框架,称为调用框架。当前函数的局部变量存储在每个堆栈帧中。
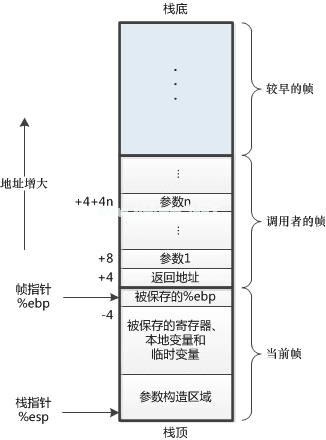
当一个函数被调用时,它被添加到调用栈的顶部,并且在执行之后,它被从调用栈的顶部移除。并在此时将运行的程序(帧指针)赋予堆栈顶部的堆栈帧。这种后进先出的结构也是函数的调用栈。
在JavaScript中,通过方法console.trace()可以方便地查看当前函数的调用框架

尾部呼叫
在你说尾递归之前,你必须知道什么是尾调用。简单来说,函数执行的最后一步是调用另一个函数并返回它。
以下是正确的演示:
//结束调用正确演示1.0函数f(x){ return g(x);}//最后一次调用正确演示了2.0函数f(x){ if(x 0){ return m(x)} return n(x);} 1.0程序的最后一步是执行函数g并返回其返回值。在2.0中,尾调用不必写在最后一行,只要它是执行时的最后一个操作。
以下是错误演示:
//尾调用错误演示1.0函数f(x){ let y=g(x);返回y;}//结束调用错误演示2.0函数f(x){ return g(x)1;}//结束调用错误演示3.0函数f(x){ g(x);//这一步相当于g(x)return undefined } 1.0的最后一步是赋值操作,2.0的最后一步是加法操作,3.0隐式有一个return undefined语句
尾部调用优化
在调用栈部分,我们知道当一个函数A调用另一个函数B时,会形成一个栈帧,调用栈中既有调用帧A,也有当前帧B。这是因为函数B的执行完成后,需要将执行权返回给A,那么函数A内部的变量和调用函数B的位置必须保存在调用框架A中,否则当函数B完成执行并继续执行函数A时,就会混淆。
现在我们把函数B放入函数A的最后一次调用(也就是尾调用),那么有必要保留函数A的栈帧吗?当然不是,因为它的调用位置和内部变量以后都不会用到。因此,直接用函数B的栈帧替换函数a的栈帧.当然,如果内部函数使用外部函数的变量,仍然需要保留函数A的栈框架,一个典型的例子就是闭包。
网上有很多关于解释尾号的博客文章,其中一篇广为流传的文章中有这样一段话。我不太同意。
函数f() {让m=1;设n=2;返回g(m ^ n);} f();//相当于函数f(){ return g(3);} f();//相当于g(3);以下是博客原文:在上面的代码中,如果函数g在最后没有被调用,函数f需要保存内部变量m和n的值,g的调用位置等信息。但是调用g之后,函数f就完成了,所以f()的调用记录可以完全删除,只保留g(3)的调用记录。
但是我认为在第一个中,首先执行m n的操作,然后同时调用函数g返回。这应该是尾号。同时m n的值也是通过参数传递到函数g中的,并没有直接引用,所以不能说f里面的变量的值都需要保存。
一般来说,如果所有函数都作为尾调用调用,调用栈的长度会小很多,这样会大大减少所需的内存。这就是尾号优化的意思。
尾部递归
递归是指在函数定义中使用函数本身的一种方法。函数调用本身叫做递归,然后函数在尾部调用自己,这叫做尾部递归。
最常见的递归,斐波那契数列,最常见的递归写法:
函数f(n){ if(n===0 | | n===1)return n else return f(n-1)f(n-2)}的编写简单粗暴,但有严重的问题。调用栈随着n的增加而线性增加,当n是一个大数字时(我测量过,当n为100时,浏览器窗口会卡住。),堆栈会爆炸(堆栈溢出)。这是因为在这个递归操作中,同时保存了大量的栈帧,调用栈非常长,消耗了巨大的内存。
接下来,将普通递归升级为尾部递归。
函数f tail (n,a=0,b=1) {if (n===0)返回一个返回f tail (n-1,b,a b)}显然是由
复制代码如下:ftail (5)=ftail (4,1,1)=ftail (3,1,2)=ftail (2,2,3)=ftail (1,3,5)=ftail (0,5,8)=return 5
调用栈经过尾部递归重写后,始终更新当前栈帧,完全避免了栈爆炸的危险。
不过思路是好的,从尾调用优化到尾递归优化的出发点是正确的,不过还是来看看V8引擎官方团队的解释吧。
适当的尾部调用已经实现,但尚未发货,因为TC39目前正在讨论对该功能的更改。
意思是人家已经做了,却忍不住替你用:)嗨,好生气。
当然,人们肯定有他的正当理由:
在引擎级别消除尾部递归是一种隐式行为。程序员在编写代码时,可能没有意识到自己已经编写了无限循环的尾部递归,在无限循环发生后,也不会报告栈溢出的错误,难以区分。堆栈信息会在优化过程中丢失,这使得开发人员很难进行调试。我理解所有的原因,但是我采用了nodeJs(v6.9.5)并手动测试了它:
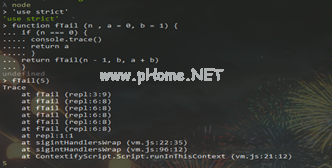
好的,我要了
手动优化
虽然暂时不能使用ES6的尾部递归高端优化,但递归优化的本质是减少调用栈,避免过度占用内存和栈爆炸的危险。俗话说,所有可以递归写的函数都可以循环写——尼古拉斯夏。如果递归变成循环,这个调用栈问题就解决不了。
方案一:直接改变内部函数,循环执行
函数flop (n,a=0,b=1) {while (n-) {[a,b]=[b,ab]} return a}简单粗暴,但缺点是不用递归更容易理解。
方案二:蹦床(蹦床功能)
function蹦床(f){ while(f f instance of Function){ f=f()} return f } Function f(n,a=0,b=1) { if (n 0) { [a,b]=[b,A b] return f. bind (null,n-1,A,b)} else {return a}}蹦床(f (5))//return 5很容易理解,也就是蹦床的功能需要仔细研究。另一个缺点是需要修改原始函数的内部写法。
方案三:尾部递归函数循环的方法
函数TailCalloptimize(f){ let value let active=false const累计=[]返回函数累加器(){累计. push(参数)if(!active){ active=true while(aggregated . length){ value=f . apply(this,aggregated . shift())} active=false返回值} } } const f=tailkaloptimize(function(n,a=0,b=1) { if (n===0)返回一个返回f(n - 1,B,a b)})f(5) //return 5在被tailkaloptimize打包后返回一个新的函数累加器,在f执行时实际执行。这种方法不需要修改原有的递归函数,在调用递归时,只需要用这种方法转置一次就可以解决递归调用的问题。
摘要
尾部递归优化是好事,但既然暂时不能用,那就要对平时编码过程中使用递归的地方特别敏感,避免循环不完、栈爆炸的危险。毕竟好工具不如好习惯。
以上就是本文的全部内容。希望对大家的学习有帮助,支持我们。
版权声明:详细解释JavaScript调用栈、尾部递归和手动优化是由宝哥软件园云端程序自动收集整理而来。如果本文侵犯了你的权益,请联系本站底部QQ或者邮箱删除。
















