Mysql中分页查询两种解决方案的比较
mysql中分页查询有两种方式,一种是使用count (*),具体代码如下:从foo中选择COUNT(*),其中b=1;选择一个FROM foo,其中b=1限制100,10;另一种是使用SQL _ calc _ found _ rows复制代码如下:从foo中选择SQL _ calc _ found _ rows a其中b=1限制100,10;SELECT FOUND _ ROWS();第二种方式,调用SQL _ CALC _ find _ ROWS后,WHERE语句查询的行数将放在find _ ROWS()中,只有第二次查询find _ ROWS()才能找到行数。讨论这两种方法的优缺点:第一,原子性,第二种方法肯定比第一种好。第二个可以保证查询语句的原子性。第一个是当两个修改表的请求之间有额外的操作时,结果自然是不准确的。而第二个没有。但不幸的是,当页面需要以分页方式显示时,分页结果往往不要求非常准确。也就是说,分页返回的总数是大一个还是小一个并不重要。因此,原子性不是我们分页的重点。让我们看看效率。这一点非常重要。分页操作在每个网站上都很常用,查询量自然很大。无论哪种方式,分页操作中一定有两个sql查询,所以关于这两个查询的性能有很多比较:SQL _ CALC _ find _ ROWS真的很慢吗?http://hi . Baidu.com/thinking in lamp/item/b 122 fdaea 5 ba 23 f 614329 b 14 To SQL_CALC_FOUND_ROWS还是不To SQL _ CALC _ FOUND _ ROWS?3358 www.mysqlperformanceblog.com/2007/08/28/to-SQL _ calc _ find _ row-or-to-SQL _ calc _ find _ row/老王本文提到了一个覆盖索引的概念。简单来说,就是如何让查询只根据索引返回结果,而不是表查询。具体见他的另一篇文章:covering index 3358 hi . Baidu.com/thinking in lamp/item/1b 9 AAF 09014 acce 0 f 45 ba 6d 3 MySQL的实验结合了这些文章。实验:表:复制代码如下:如果不存在创建表` foo` (`a`int (10)无符号不为null auto _ increment,` b`int (10)无符号不为null,` c` varchar(100) NOT NULL,PRIMARY KEY (`a `),KEY `bar` (`b `,` a `))ENGINE=MyISAM;注意这里用b和a做索引,所以查询select *时不使用覆盖索引,覆盖索引用于select a复制代码如下:PHP $ host=' 192 . 168 . 100 . 166 ';$ dbName=' test$ user=' root$ password=$db=mysql_connect($host,$user,$password)或die(' DB connect failed ');mysql_select_db($dbName,$ db);回声'====================================================='。\ r \ n ';$ start=micro time(true);for($ I=0;$ i1000$ I){ MySQL _ query(' SELECT SQL _ NO _ CACHE COUNT(*)FROM foo WHERE b=1 ');MySQL _ query(' SELECT SQL _ NO _ CACHE a FROM foo WHERE b=1 LIMIT 100,10 ');} $ end=micro time(true);echo $end - $start。\ r \ n ';回声'====================================================='。\ r \ n ';$ start=micro time(true);for($ I=0;$ i1000$ I){ MySQL _ query(' SELECT SQL _ NO _ CACHE SQL _ CALC _ find _ ROWS a FROM foo WHERE b=1 LIMIT 100,10 ';MySQL _ query(' SELECT FOUND _ ROWS()');} $ end=micro time(true);echo $end - $start。\ r \ n ';回声'====================================================='。\ r \ n ';$ start=micro time(true);for($ I=0;$ i1000$ I){ MySQL _ query(' SELECT SQL _ NO _ CACHE COUNT(*)FROM foo WHERE b=1 ');MySQL _ query(' SELECT SQL _ NO _ CACHE * FROM foo WHERE b=1 LIMIT 100,10 ');} $ end=micro time(true);echo $end - $start。\ r \ n ';回声'====================================================='。\ r \ n ';$ start=micro time(true);for($ I=0;$ i1000$ I){ MySQL _ query(' SELECT SQL _ NO _ CACHE SQL _ CALC _ find _ ROWS * FROM foo WHERE b=1 LIMIT 100,10 ';MySQL _ query(' SELECT FOUND _ ROWS()');} $ end=micro time(true);echo $end - $start。\ r \ n ';返回的结果: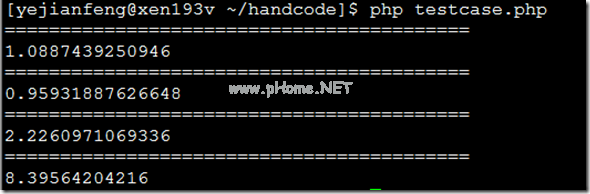
和老王的文章一样。SQL _ CALC _ find _ ROWS的第四个查询不仅没有使用覆盖索引,还需要全表查询,而COUNT(*)和select *的第三个查询没有使用索引,所以有这么大的区别。总结PS:还有一个提醒,这里用MyISAM的时候三个查询和四个查询会有这么大的区别,但是如果用InnoDB的话就不会有这么大的区别了。因此,我得出结论,如果数据库是InnoDB,我仍然更喜欢使用SQL _ CALC _ find _ ROWS。结论:SQL _ CALC _ find _ ROWS和COUNT(*)在使用覆盖索引时性能较高,但在不使用覆盖索引时性能较高。所以使用的时候要注意这一点。
版权声明:Mysql中分页查询两种解决方案的比较是由宝哥软件园云端程序自动收集整理而来。如果本文侵犯了你的权益,请联系本站底部QQ或者邮箱删除。
















