Python新手爬虫二:爬取搜狗图片(动态)
时间:2020-04-02 来源:互联网 编辑:宝哥软件园 浏览:34次
经过上一期爬取豆瓣影评成功后,感觉爬虫还不错,于是想爬点图片来玩玩...
搜狗图片地址:https://pic.sogou.com/?from=category
先上最后成功的源码:
import requests
import urllib
import json
from fake_useragent import UserAgent
def getSougouImag(category,length,path):
n = length
cate = category
imgs_url = [] #定义空列表,用于保存图片url
m = 0 #用于显示图片数量
url = 'https://pic.sogou.com/pics/channel/getAllRecomPicByTag.jsp?category='+cate+'&tag=%E5%85%A8%E9%83%A8&start=0&len='+str(n)
headers = {'user-agent':UserAgent().random} #设置UA
f = requests.get(url,headers=headers) #发送Get请求
print(f.status_code)
js = json.loads(f.text)
js = js['all_items']
for j in js:
imgs_url.append(j['thumbUrl'])
for img_url in imgs_url:
print('***** '+str(m)+'.jpg *****'+' Downloading...')
urllib.request.urlretrieve(img_url,path+str(m)+'.jpg') #下载指定url到本地
m += 1
print('Download complete!')
getSougouImag('壁纸',500,r'D:souGouImg/')效果图:
")
下面开始介绍作为一个新手的爬虫步骤...
1、首先打开网页查看HTML源码
先按F12打开调试界面—>右击图片—>点击检查
会出现如下图红框中的信息,不难看出,此图片的url就是img标签中src属性的值。
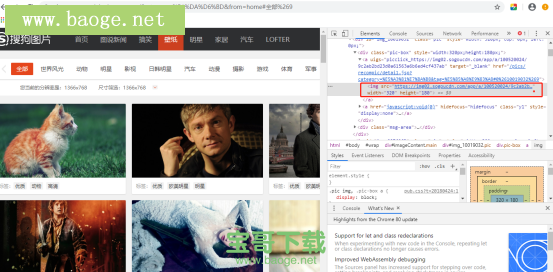
如此简单?那直接获取src属性的值,再进行下载不就完全ok了?
话不多说,开干。
from bs4 import BeautifulSoup
import requests
from fake_useragent import UserAgent #ua库
url = 'https://pic.sogou.com/pics/recommend?category=%B1%DA%D6%BD&from=home#%E5%85%A8%E9%83%A8%269'
headers = {'user-agent':UserAgent().random} #设置UA
f = requests.get(url,headers=headers) #发送Get请求
print(f.status_code) #打印状态码
soup = BeautifulSoup(f.text,'lxml') #用lxml解析器解析该网页的内容
print(soup.select('img')) #筛选出所有img的标签,并打印其属性和内容代码执行结果如下:

发现打印出的html并不是与网页中的一致,所有考虑,这根本不是图片的源url,于是推测图片是动态的,继续查找... 也是百度到了某个大佬的文章,才挖掘出以下搜寻方法。
2、点击NetWork—>点击XHR—>然后往下滚轮,使它加载出新的图片—>点击新加载出来的图片—>再点击右侧的Preview

发现Preview下的内容为json格式的
发现all_items,点击它发现有0.....众多数字,再点开发现有许多url,粘贴到浏览器中查看,发现这些都是图片的url(心中狂喜)
找到图片的真实URL,问题也就变得简单了。详情还是请看代码注释吧~
版权声明:Python新手爬虫二:爬取搜狗图片(动态)是由宝哥软件园云端程序自动收集整理而来。如果本文侵犯了你的权益,请联系本站底部QQ或者邮箱删除。
















