python中正则表达式的详细说明
自从学习Python后,发现Python经常被用作工具。尤其是在文本处理中,它很容易使用。
说到文本处理,正则表达式一定是一个极好的工具,它可以非常简洁的方式搜索或替换一些复杂的字符。
当我们处理文本时,我们要么查询并抓取它,要么替换它。
1.搜索如果你想自己实现这样的功能模块,输入一个ip地址,获取ip地址所在区域的详细信息。
然后你会发现http://ip138.com可以找到非常详细的数据
但是人们没有为外部调用提供api,但是我们可以通过代码模拟查询,然后抓取结果。
通过查看这个对应页面的源代码,我们可以发现结果被放置在三个li/li中
复制代码如下:表宽=' 80% '边框=' 0 ' align=' center ' cell padding=' 0 ' cell spacing=' 0 ' Tr TD align=' center ' h3ip138.com IP查询(搜索IP地址的地理位置)/H3/TD/Tr TD align=' center ' h1您查询的IP是:121 . 0 . 29 . 231/h1/TD/Tr Tr TD align=' center ' ul class=' ul1 ' liMaster本网站数据:阿里巴巴, 浙江省杭州市/Li/ul/TD/tr TD align=' center '如果您发现查询结果不详细或不正确,请使用a href='ip_add.asp? Ip=121 . 0 . 29 . 231 ' font color=' # 006600 '自助添加IP数据库/font/a函数以更正br/br/iframe src=' http :/jss/BD _ 460 X60 . htm ' frame border=' no ' width=' 460 ' height=' 60 ' border=' 0 ' margin width=' 0 ' marginheight=' 0 '滚动=' no '/iframe br/br//TD/aTr td align='center'IP地址或域名:输入类型=' text' name=' IP' size=' 16 '输入类型=' submit' value=' query '输入类型=' hidden ' name=' action ' value=' 2 '/TD/trbrbr/form/table
如果你知道正则表达式,你可能会写
正规表达式
复制代码如下:(?=li)。*?(?=/li)
这里用的是前瞻:向前看,向后看:这样做的好处是匹配结果将不包含html li标记。
如果你对自己的正则表达式没有信心,可以在一些在线或者本地的正则测试工具上做一些测试,确保它们的正确性。
接下来的工作是,如果我们使用Python来实现这个函数,我们必须首先表达正则表达式:
复制代码如下:r '(?=li)。*?(?=/li)
在Python中,前导的R字符加在字符串前面,这意味着字符串是R aw String(原始字符串),也就是说Python字符串本身不会转义字符串中的字符。这是因为正则表达式也有转义字符,如果是双转义的话可读性很差。
这个字符串在Python中被称为“正则表达式模式”
如果我们编译模式,
复制代码如下:prog=re.compile(r '(?=li)。*?(?=/li)')
我们可以得到一个正则表达式对象,正则表达式对象,通过它我们可以执行相关的操作。
例如
复制代码如下:结果=Prog。match (string) # #这相当于result=re.match(r '(?=li)。*?(?=/li)',string) ##但是如果这个规则需要在程序中多次匹配,那么传递正则表达式对象会更有效率
下一步是搜索,假设我们的html结果已经以html格式存储在文本中,然后传递
复制代码如下:result_list=re.findall(r '(?=li)。*?(?=/li)',文本)
您可以获得所需的结果列表。
2.替换使用正则表达式非常灵活。
比如我之前在Trac系统中阅读wiki模块的源代码时,发现wiki语法的实现是通过正则替换的。
使用替换时,将涉及正则表达式中的分组概念。
假设使用了维基语法!指示转义字符,即感叹号后的功能字符,将按原样输出。粗体的语法是
上面写着‘‘’在这里用粗体显示''然后有一个正则表达式如下
复制代码如下:r '(?Pbold!''')'
这里吗?Pbold是Python常规语法的一部分,这意味着以下组的名称是“粗体”
下面是替换场景,子函数的第一个参数是pattern,第二个参数可以是string或者function。如果是字符串,则用指定的结果替换目标匹配的结果,如果是函数,则函数接受匹配对象参数并返回替换后的字符串,第三个参数为源字符串。
复制代码如下:result=re.sub(r '(?Pbold!'')',替换,行)
每当匹配三重单引号时,替换函数将运行一次。此时可能需要一个全局变量来记录当前三重单引号是开还是关,以便添加相应的标记。
在trac wiki的实际实现中,这就是如何通过一些标签变量来记录一些语法标签的打开和关闭,从而确定replace函数的运行结果。
-
例子
1.判断字符串是否全部小写
密码
复制的代码如下: #-*-coding : CP 936-*-import res1=' adkkdk ' S2=' ABC 123 EFG '
An=re.search ('[a-z] $ ',S1)如果an:print的s1: ',an.group(),'全小写' else 3360prints1,'全小写!'
An=re。match ('[a-z] $ ',s2)如果:打印机的s2: ',an.group(),'全小写' else:打印机的S2,'全小写!'
结果

调查其原因
1.正则表达式不是python的一部分,它在使用时需要引用re模块
2.匹配的形式是re.search(带有匹配字符串的正则表达式)或re.match(带有匹配字符串的正则表达式)。两者的区别在于后者默认以starter()开始。因此,
Re.search ('[a-z] $ ',S1)相当于re.match('[a-z] $ ',s2)3。如果匹配失败,an=re.search ('[a-z] $ ',S1)将返回None
组用于对匹配结果进行分组
例如
复制代码如下:导入rea=' 123abc456 '打印re。搜索('([0-9] *) ([a-z] *) ([0-9] *)',a)。group(0)# 123 ABAC 456,整个printre . search(([0-9]*)([a-z]*)([0-9]*)',a)。group(1)# 123 printree . search(([0-9]*)([a-z]*)
1)正则表达式中的三组括号将匹配结果分为三组
Group()和group(0)是匹配正则表达式的全部结果
组(1)列出了第一个括号匹配零件,组(2)列出了第二个括号匹配零件,组(3)列出了第三个括号匹配零件。
2)如果没有成功匹配,重新搜索()将返回无
3)郑的表述当然没有括号,组(1)肯定是错的。
二.缩略语的扩展
具体例子
联邦应急管理局爱尔兰共和党武装力量民主统一党
美国食品和药物管理局OLC法律顾问办公室分析
缩写FEMA分解为F*** E*** M*** A*** *常规大写字母小写(大于等于1)空格参考码
复制代码如下: import redef expand _缩写(sen,缩写): len缩写=len(缩写)ma='' for I in range (0,len缩写): ma=缩写[I]'[a-z]' ' print ' ma : ',ma ma=ma . strip(')p=re . search(ma,sen)if p : return p . group()else 3360 return ' '
print expand _缩写('欢迎来到中国农业银行',' ABC ')
结果

问题
上面的代码对于前三个例子是正确的,但是后两个是错误的,因为以大写字母开头的单词之间也有小写字母
法律
大写字母是小写(1或更多)空格[小写空格](0次或1次)
参考码
复制代码如下: import redef expand _缩写(sen,缩写): len缩写=len(缩写)ma='' for I in range (0,len缩写-1) 3360 ma=缩写[I]'[a-z]' ' '([a-ma]=缩写[len缩写-1] '[a-z] ' print 'ma: ',ma ma ma=ma . strip(')p=re . search(ma,sen)if p3f
print expand _缩写('欢迎来到中国农业银行',' ABC ')
技能
中间小写字母设置一个空格,作为一个整体,添加一个括号。要么同时拥有,要么不同时拥有,所以需要?匹配前面的整体。
3.删除数字中的逗号
具体例子
在处理自然语言时,如果123,000,000用标点符号除,就会出现问题,好的数字会被逗号肢解,可以先把数字清理干净(去掉逗号)。
分析
数字通常由三个数字后跟一个逗号组成,因此规则为:* * *、* * *、* * *
正规表达式
[a-z],[a-z]?
参考代码3-1
复制代码如下:导入re
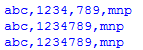
sen='abc,123,456,789,MNP ' p=re.compile(\d,\ d?)
对于p . finditer(sen):mm=com . group()中的com打印“hi:”,mm打印“sen_before:”,sen=sen.replace(mm,mm.replace(',',''))打印“sen_back:”,sen,' \n '
结果

技能
使用函数findier(字符串[,pos [,endpos]]) | re。findier(模式、字符串[、标志]) :
搜索字符串并返回一个迭代器,该迭代器按顺序访问每个匹配结果(匹配对象)。
参考代码3-2
复制代码如下:sen=' ABC,123,456,789,MNP '而1:mm=re . search(' d,\ d ',sen)if mm 3360mm=mm . group()sen=sen . replace(mm,mm
结果

扩展
这个程序是针对具体问题的,也就是把数字分成三位数。如果数字和字母混在一起,数字之间的逗号被去掉,即“abc,123,4,789,mnp”转换为“abc,1234789,mnp”
思考
更具体地说,找到常规的“数字,数字”,并用逗号替换它们
参考代码3-3
复制代码如下:sen=' ABC,123,4,789,MNP '而1:mm=re.search ('\ d,d ',sen)如果mm 3360mm=mm . group()sen=sen . replace(mm,mm.replace)
结果
4.中文处理的年份转换(例如,1949-1949)
中文处理涉及编码问题。例如,当下面的程序识别年份(* * * *)时,
复制代码如下: #-*-coding : CP 936-*-importrem 0='新中国成立于1949年' m1='比1990年下降5.2% ' m2='人民在1996年打败了俄军,实现了实质性独立'
Def fuc(m): a=re.findall('零|一|二|三|四|五|六|七|八|九]年',m)如果a:为键则在a:打印键else 3360打印' null '
fuc(m0)fuc(m1)fuc(m2)
运行结果

可以看出,第二个和第三个都犯了错误。
将——规范化改进为unicode识别
复制代码如下: #-*-coding : CP 936-*-importrem 0='新中国成立于1949年' m1='比1990年下降5.2% ' m2='人民在1996年打败了俄军,实现了实质性独立'
def fuc(m):m=m . decode(' CP 936 ')a=re . findall(u '[\ u96 F6 | \ u4e 00 | \ u4e 8c | \ u4e 09 | \ u56db | \ u4e 94 | \ u 516d | \ u4e 03 | \ u516 b | \ u4e 5d]\ u5e 74 ',m)
如果a:中的键为a:打印键else:打印“空”
fuc(m0)fuc(m1)fuc(m2)
结果

识别后,汉字可以用数字代替。
涉及
复制代码如下:numHash={}numHash['零'。解码(' utf-8')]='0'numHash['一'。decode(' utf-8 ')]=' 1 ' NumHash[' two '。decode ('utf-8')='2'numHash['三'。解码(' utf-8')]='3'numHash['四'。解码(' utf-8')]='4'numHash['五'。decode(' utf-8 ')]=' 5=' 6 ' NumHash[' seven '。解码(' utf-8')]='7'numHash['八'。decode(' utf-8 ')]=' 8 ' NumHash[' nine '。解码(' utf-8')]='9 '
def change 2 num(word):打印' words: ',word newword=' word :中的键打印键如果numHash:中的键new word=numash[key]else : new word=键返回new word
def Chi2Num(行): a=re . findall(u '[\ u96 F6 | \ u4e 00 | \ u4e 8c | \ u4e 09 | \ u56db | \ u4e 94 | \ u516 d | \ u4e 03 | \ u516 b | \ u4e 5d]\ u5e 74 ',行)如果a 3360 print '-'为a 3360 new words=change 2 num(单词)中的单词打印行打印新单词行=行。
版权声明:python中正则表达式的详细说明是由宝哥软件园云端程序自动收集整理而来。如果本文侵犯了你的权益,请联系本站底部QQ或者邮箱删除。
















