NodeJS制作爬虫的全过程
今天就来学习一下alsotang的爬虫教程,然后简单的爬CNode。
建立项目craelr-demo我们首先建立一个Express项目,然后删除app.js文件的所有内容,因为我们暂时不需要在Web端显示内容。当然,我们也可以直接在空文件夹中使用npm install Express来使用我们需要的Express功能。
网络分析如图所示。这是CNode主页上的一个div标签。我们使用这一系列id和类来定位我们需要的信息。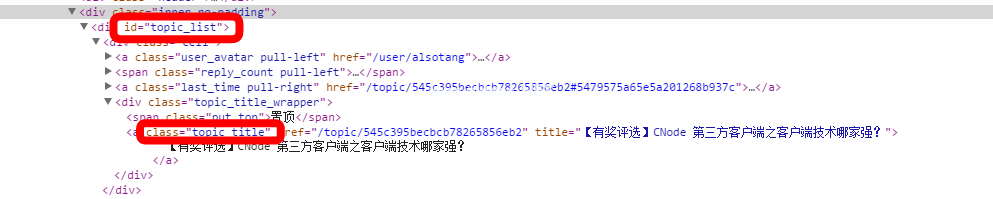
使用superagent获取源数据。
Superagent是ajax API使用的Http库,其使用方法类似于jQuery,我们通过jQuery发起get请求,并在回调函数中输出结果。
复制代码如下: var Express=require(' Express ');var URL=require(' URL ');//解析操作URL var super agent=require(' super agent ');//不要忘记三个外部依赖:NPM安装var chef=require(' chef ');var event proxy=require(' event proxy ');var TargetURl=' https://cnodejs . org/';superagent.get(targetUrl)。end(function (err,RES){ console . log(RES);});
它的res结果是一个包含目标url信息的对象,网站内容主要在其文本(字符串)中。
用cheerio解析。
Cheerio在服务器端充当jQuery函数。我们首先使用它的。load()加载HTML,然后通过CSS选择器过滤元素。
复制代码如下: var $=chef . load(RES . text);//筛选数据$ ('# topic _ list.topic _ title ')。每个(function (idx,element){ console . log(element);});
结果是一次一个对象。打电话给。每个(函数(索引,元素))函数遍历每个对象并返回HTML DOM Elements。
输出console . log($ element . attr(' title '));结果是2014年12月6日广州NodeParty的UC农场标题,输出是console . log($ element . attr(' href ');结果是一个url,如/topic/545 c 395 becbcb 78265856 EB 2。然后使用NodeJS1的url.resolve()函数完成完整的url。
复制代码如下: superagent.get (turl)。end (function (err,RES) {if (err) {return console。错误(err);} var topiculps=[];var $=cheerio . load(RES . text);//获取所有链接$ ('# topic _ list.topic _ title ')。每个(function (idx,element){ var $ element=$(element);var href=url.resolve(tUrl,$ element . attr(' href '));console . log(href);//topiculps . push(href);});});
使用eventproxy同时捕获每个主题的内容的教程中显示了深度嵌套(串行)方法和计数器方法的示例。eventproxy使用事件(并行)方法来解决这个问题。当所有爬网完成时,eventproxy会接收事件消息,并自动为您调用处理函数。
复制代码如下://步骤1:获取eventproxy的实例:var EP=new event proxy();//第二步:定义监听事件的回调函数。//after方法重复监听//params 3360 event name(String)事件名称,次数(Number)监听次数,回调函数ep.after ('topic _ html ',topic URLs.length,函数(topics){ //topics是一个数组,它包含ep.emit('topic_html ',pair)中的40对40次。//.map topics=topics.map(函数(topic pair){//使用cherio var topic URL=topic pair[0];var topicHtml=topiccair[1];var $=cheerio . load(topicHtml);return ({ title: $(')。topic _ full _ title’)。文本()。trim(),href: topicUrl,comment1: $('。reply _ content’)。eq(0)。文本()。trim()});});//outcome console . log(' outcome : ');console.log(主题);});//第三步:确定topicurls.foreach(函数(topi curl){ super agent . get(topi curl))。end(函数(err,RES){ console . log(' fetch ' topicur ' success '))用于释放事件消息;ep.emit('topic_html ',[topicur,RES . text]);});});
结果如下

延伸练习(挑战)
获取消息用户名和点数。

在文章页面的源代码中找到评论的用户类名,类名为reply_author。从第一个元素$()可以看出。reply _ author’)。获取(console.log,我们需要获取的所有内容都在这里。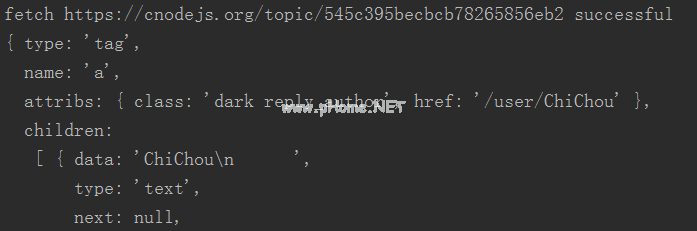
首先,我们抓一篇文章,立刻得到我们需要的一切。
复制代码如下: VAR USER href=URL . resolve(turl,$(')。reply _ author’)。获取(0)。attribs . href);console . log(userref);console.log($(')。reply _ author’)。获取(0)。儿童[0]。数据);
我们可以通过https://cnodejs.org/user/username.获取完整的信息
复制代码如下: $('。reply _ author’)。每个(function (idx,element){ var $ element=$(element);console . log($ element . attr(' href '));});
在用户信息页面$('上。大’)。文本()。trim()是积分信息。
使用函数。获取cheerio的(0)以获取的第一个元素。
复制代码如下: VAR USER href=URL . resolve(turl,$(')。reply _ author’)。获取(0)。attribs . href);console . log(userref);
这只是抓取单篇文章,对于40篇文章,还有修改的空间。
版权声明:NodeJS制作爬虫的全过程是由宝哥软件园云端程序自动收集整理而来。如果本文侵犯了你的权益,请联系本站底部QQ或者邮箱删除。
















